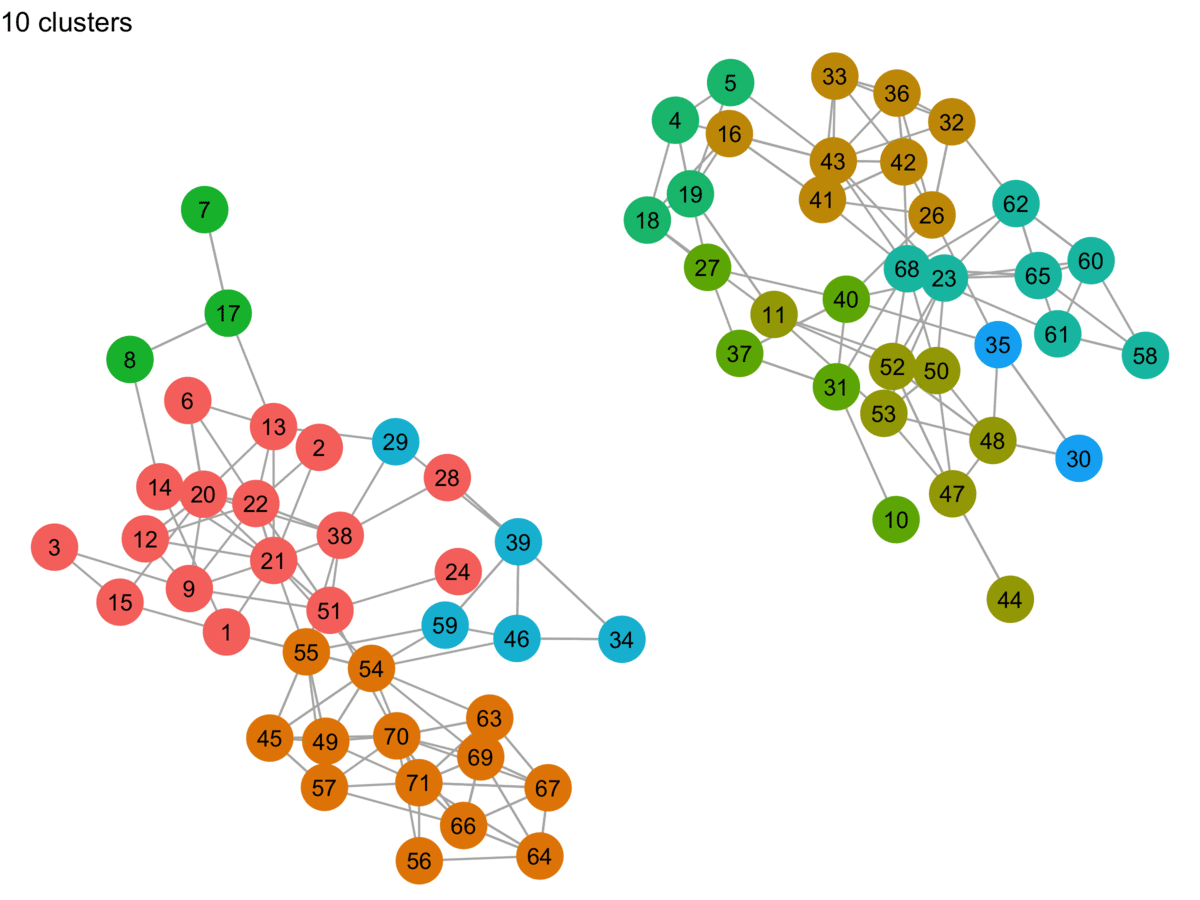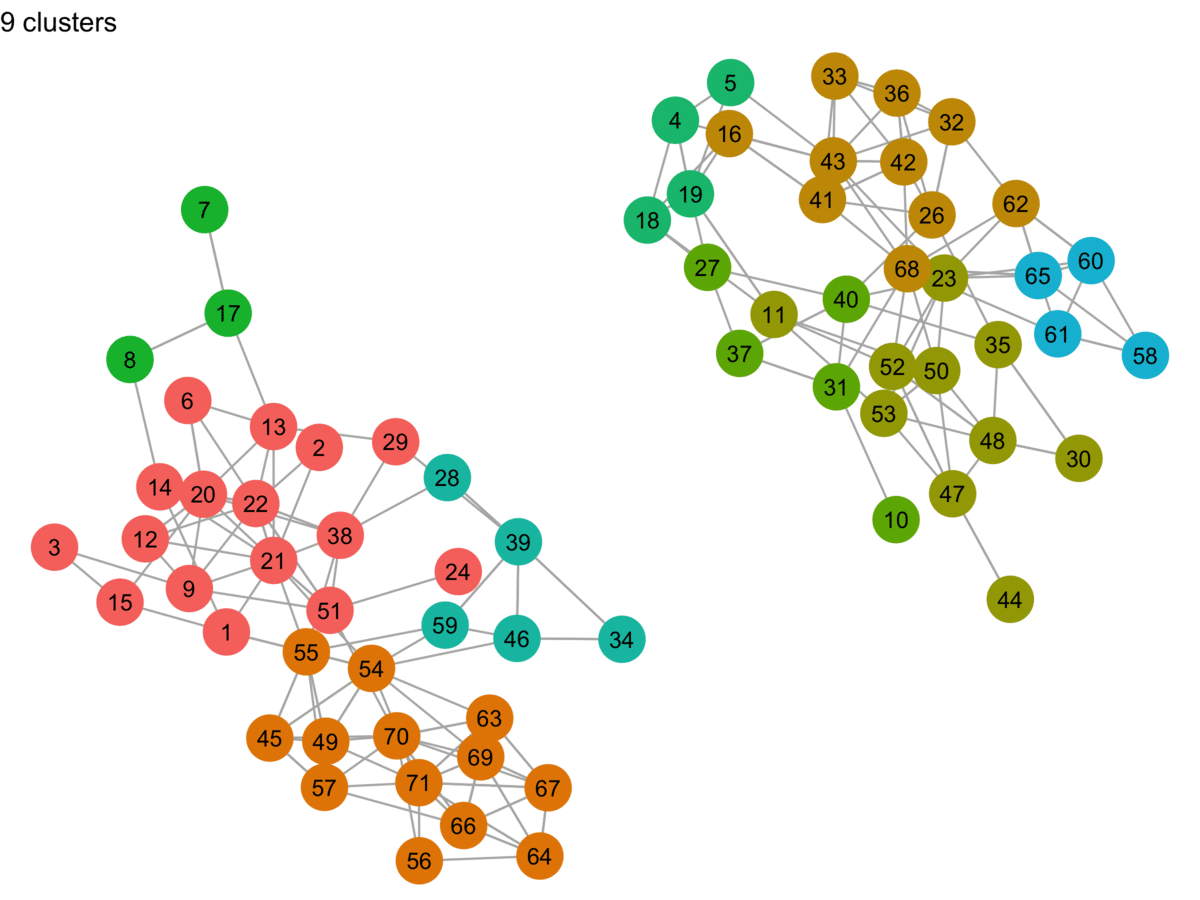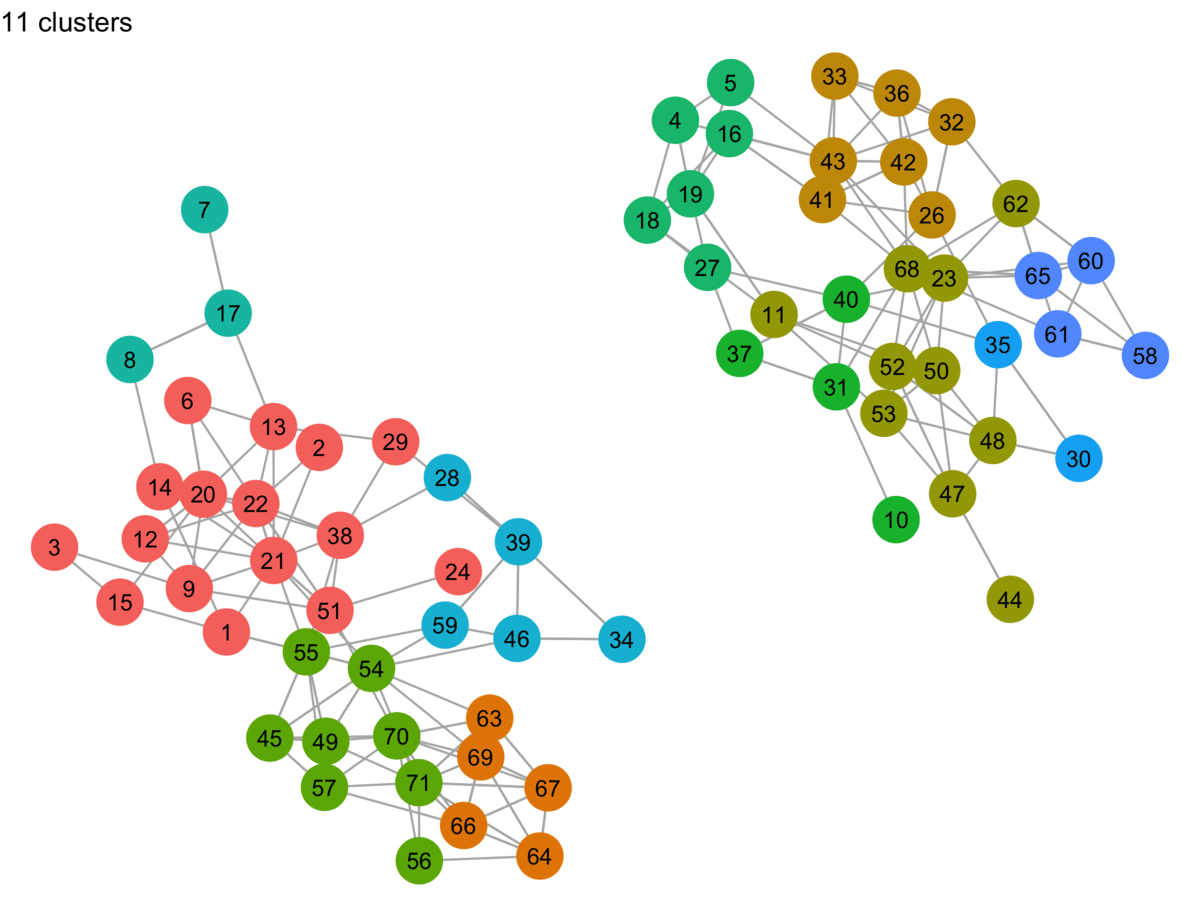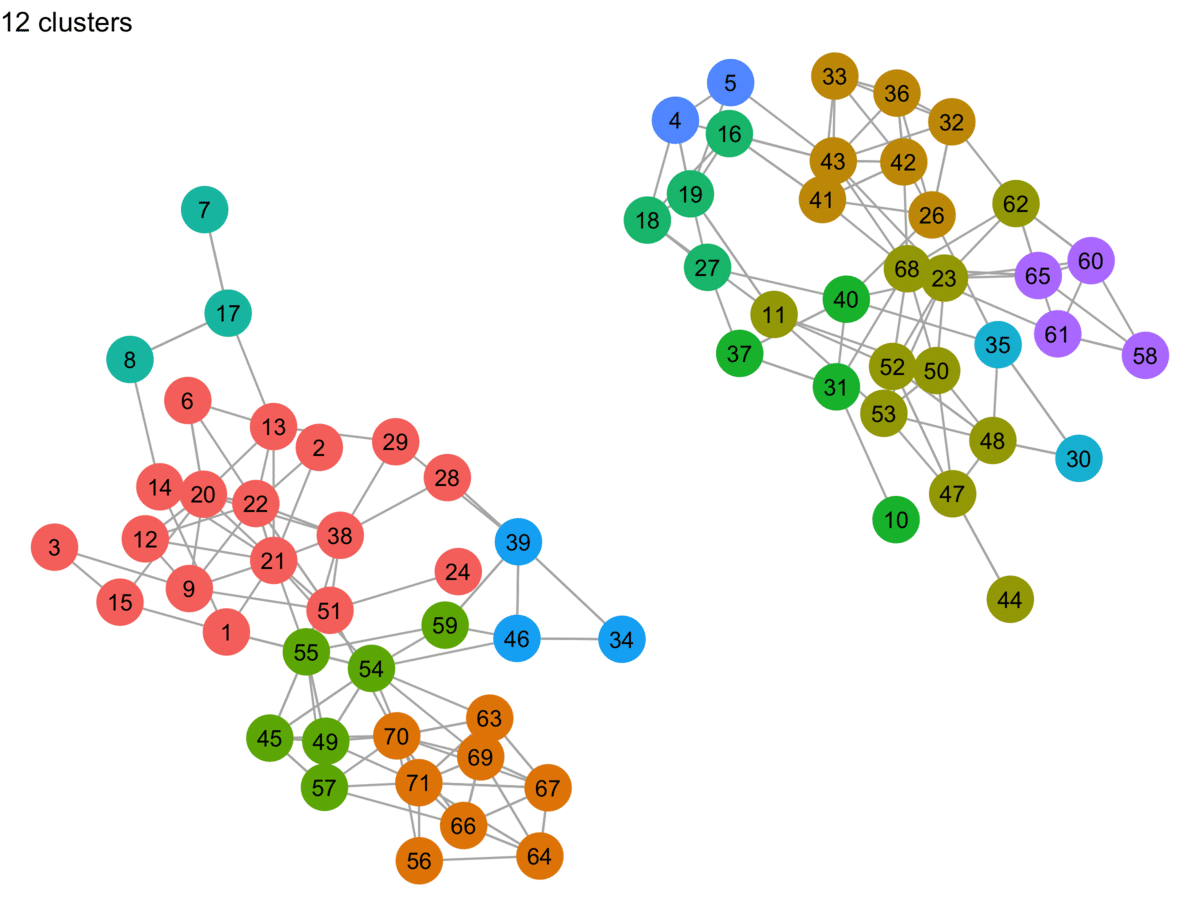
Sometimes to learn something, you just have to implement it yourself. In this post, I try my hand at approximating the Label Propagation Algorithm (LPA) proposed by Raghavan et al. in their paper, Near linear time algorithm to detect community structures in large-scale networks. It’s a fairly common (fast!) community detection algorithm that is implemented in igraph (C-based network analysis library with interfaces in R, Python, and Mathematica), GraphFrames (built on Spark, with APIs in Scala, Java, and Python–plus an R API created by RStudio), and in other places.
Requirements Step 0: install Java 8 Step 1: Install the client Step 2: Configure connection properties Step 3: set up in R Conclusion Using Databricks notebooks on their platform is not so bad, but once you want to access the super power of Spark from your local RStudio, you’ve got to prepare yoruself for some installation hell. This post augments the Databricks official documentation and spells out the steps that tripped me up.
My starting point Previewing SQL in RStudio 1. Preview a .sql file 2. SQL chunks in RMarkdown Passing variables to/from SQL chunks SQL output as a variable Providing query parameters SQL files meet chunks R & SQL – working hand-in-hand In the last year, SQL has wound its way deeper and deeper into my R workflow. I switch between the two every day, but up to now, I’ve been slow diving into the SQL tools RStudio provides.
In my recent exploration of window functions, I realized didn’t really know the differences between rank functions. The dplyr documentation lists out six functions, of which I pretty much only use one (row_number()):
row_number() ntile() min_rank() dense_rank() percent_rank() cume_dist() Though the documentation description is relatively clear, it was still hard to grasp exactly how they differed. I found it easier to do the comparison visually.
Trivia score ranks Given a toy dataset of trivia scores from two teams, let’s see how the scores rank using the functions above.
The problem SQL solution R (tidyverse) solution Syntax comparison I recently drilled down into window functions in SQL, so here’s a quick example comparing some of the syntax differences between SQL and R.
The problem We’ll start with sequence of 10 orders with an order id and amount spent ($):
library(tidyverse) library(dbplyr) #for simulating a database library(slider) #for sliding window functions sample_orders <- tibble(o_id = 101:110, spent = round(runif(10, 5, 100), digits = 2)) o_id spent 101 80.
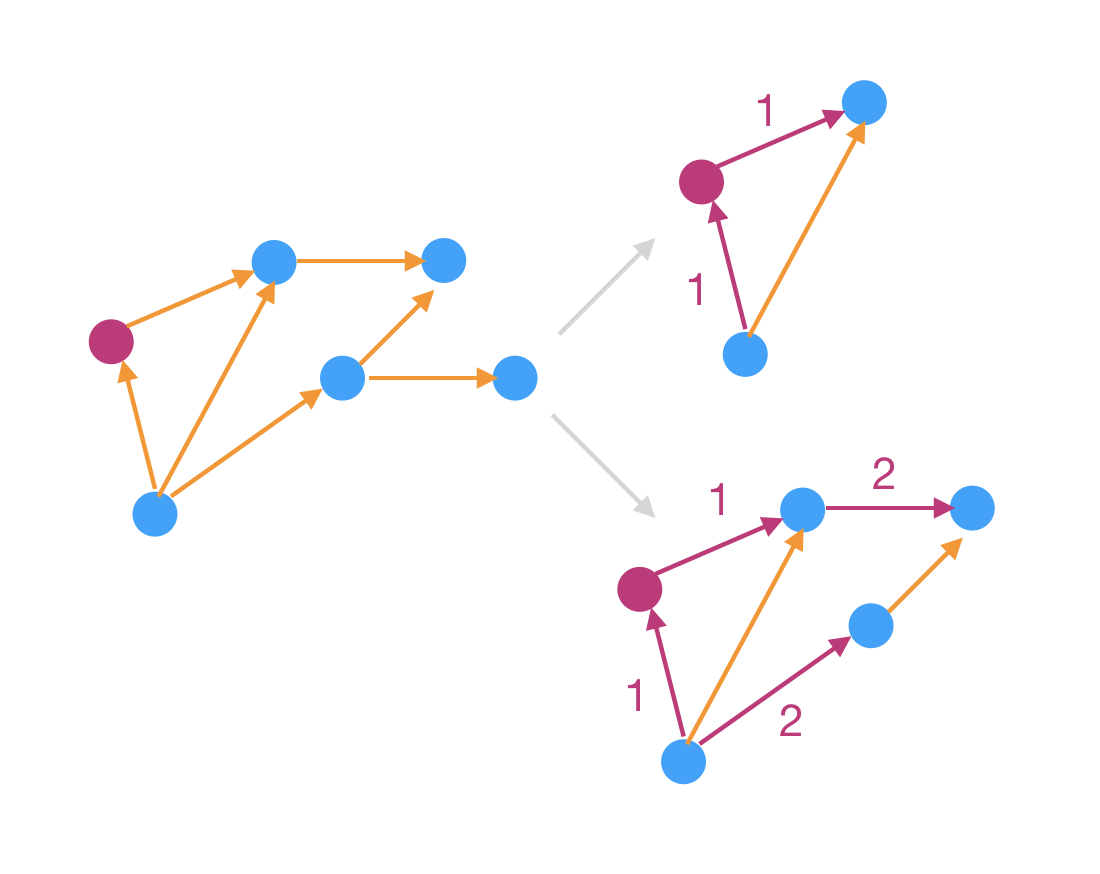
I’ve worked with igraph a few times now, but I usually dive straight into what I want to do and bash my way through. Recently I decided to review the fundamentals…annotating and diagramming to help me remember the terminology and concepts. This post is a collection of those visual notes.
I’ve worked with igraph a few times now, but I usually dive straight into what I want to do and bash my way through.

Aside from the workshops and talks at #rstudioconf back in January, I picked up many useful nuggets from the stream of conference tweets. I was particularly struck by this one:
Tired: Load R scripts with source()
Wired: Load R scripts with callr https://t.co/x2wxIOdmU0
— Travis Gerke (@travisgerke) January 18, 2019 Not feeling the amazement? Okay, let me explain…
Loyal readers may remember my previous blogpost, in which I described starting a new R process to run a plumber API for testing.

Every once in a while I complain on Twitter when I try to mix non-English letters with R. I am certainly not the first person to be frustrated by encoding issues, though I am (maybe too) hopeful that the problems won’t last for much longer. We live in the age of vacuum bots and 3D-printing, so what makes multi-language support so complicated?
Trying to mix Hebrew with #rstats is a bit of a nightmare, but at least it led me to this amazing "String encoding and R" blogpost by @kevin_ushey.

This summer, I fiddled around with plumber, an R package for creating your very own web API. I got my start with Jeff Allen’s webinar, “Plumbing APIs with plumber” (slides here). I later dug into the topic some more using the plumber bookdown, along with a lot of trial and error.
In this blogpost, I’ll highlight how I gradually improved on my plumber building/testing workflow and eventually automated my testing steps.

This summer, I teamed up with Jenny Bryan to create a series of coding puzzles, which (fingers crossed!) will be released next spring. It was exciting to start a project from the ground up, growing and shaping it over the 10-ish weeks of the internship.
Project background The Advent of Code puzzles were a major source of inspiration for the project. I spent a fair amount of my winter holidays last year solving the Advent of Code in R.